|
Optimization of residual vector quantizationIn vector quantization (VQ) problems, a residual vector is the offset of a vector from its assigned centroid. We formulate all VQ models performing quantization on residual vectors as residual quantization (RQ). It is possible to use any type of vector quantizers in residual spaces. While it falls to the plain model residual vector quantization (RVQ) if only unconstrained VQ recursively employed.The known limitation of RVQ, i.e. increased randomness in the residual spaces of mixed clusters, also exists in all RQ models. However, there exist few efficient solutions so far. We propose residual-alignment methods to address the issue by finding specific transforms to increase the correlations of residual clusters. Experimental results show our methods give substantial improvement about quantization quality to different RQ models. We also used our optimized residual product quantization (ORPQ) model to an extensive study of the problem approximate nearest neighbor search (ANN). We have achieved significant improvement, on a billion-scale SIFT dataset, of the search quality with very limited overhead of memory and speed costs comparing to other state of the art methods. |
|
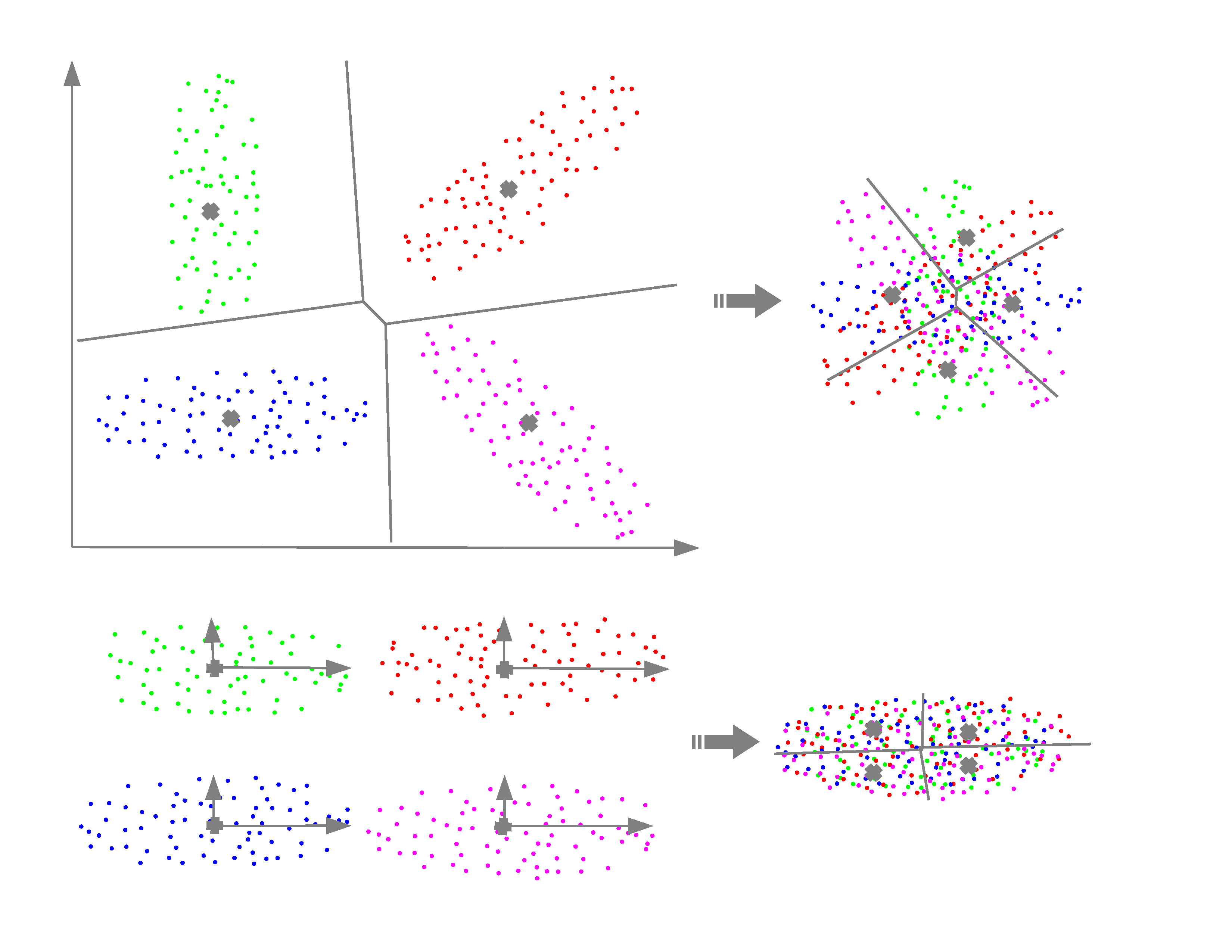
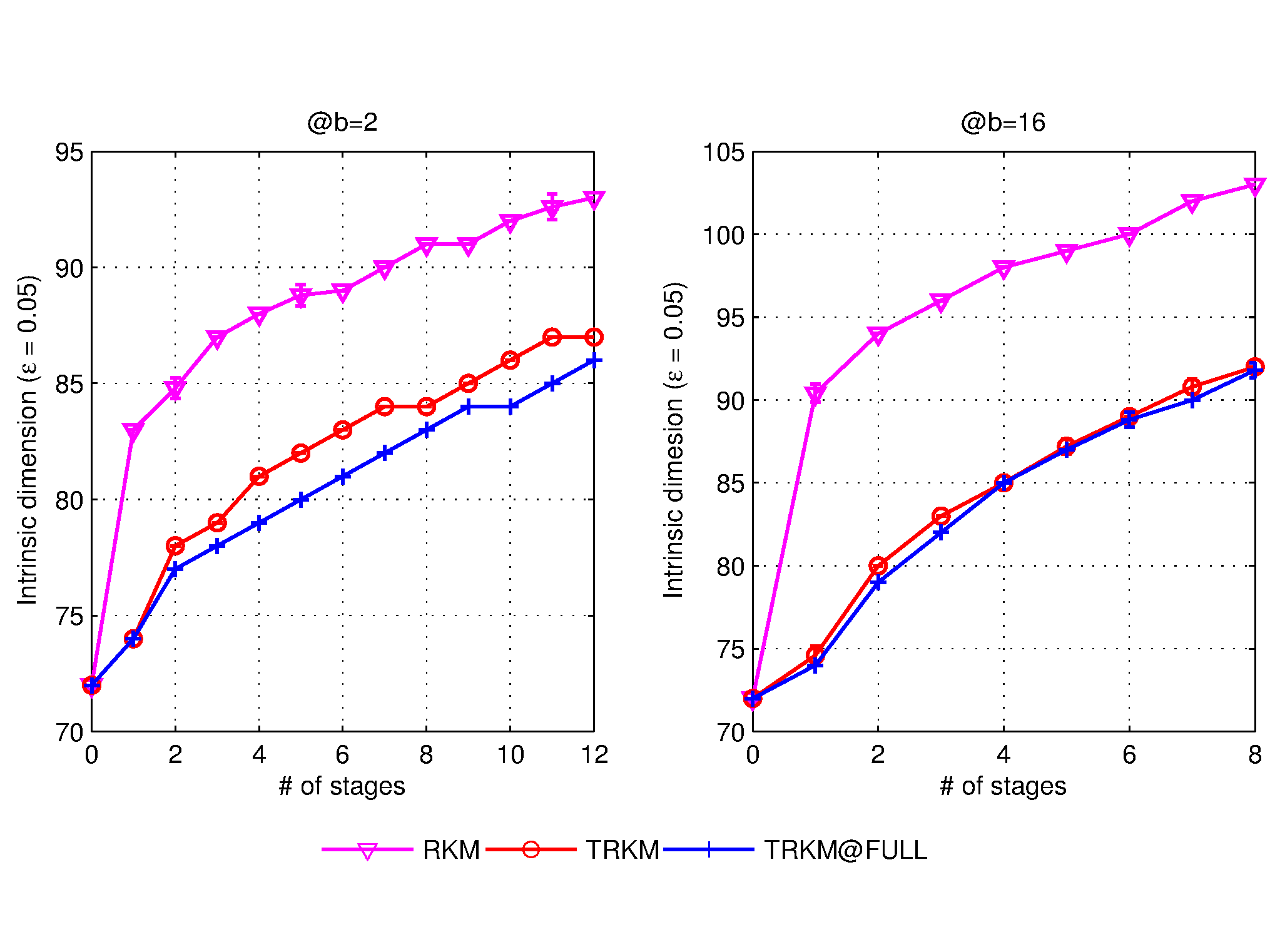
Transform residual k-means trees for scalable clusteringThe k-means problem, i.e., to partition a dataset into k clusters is a fundamental problem common to numerous data mining applications. By generating cluster centers via Cartesian products of cluster centers in multiple groups or multiple stages, product and residual k-means trees reduce computation and storage complexity, making it possible to cluster large scale datasets. As residual k-means trees do not require assumed statistical independence among groups that are required by product k-means trees, they generally give better clustering quality. A known limitation of residual k-means trees is that the gain diminishes with added stages. By identifying increased intrinsic dimensions of residual vectors with more stages as a limiting factor of performance due to the curse of dimensionality, we propose transform residual k-means trees as a generalization by applying cluster specific transforms to increase the correlations of residual vectors. Our methods substantially reduce the increase of intrinsic dimensions and therefore increase the effectiveness of multiple-stage residual k-means trees. Experimental and comparative results using widely used datasets show our methods give the best performance among all scalable methods. Furthermore, our methods enable effective super-clustering learning and provide scalable solutions to duplicate detection and other data mining problems. |
|
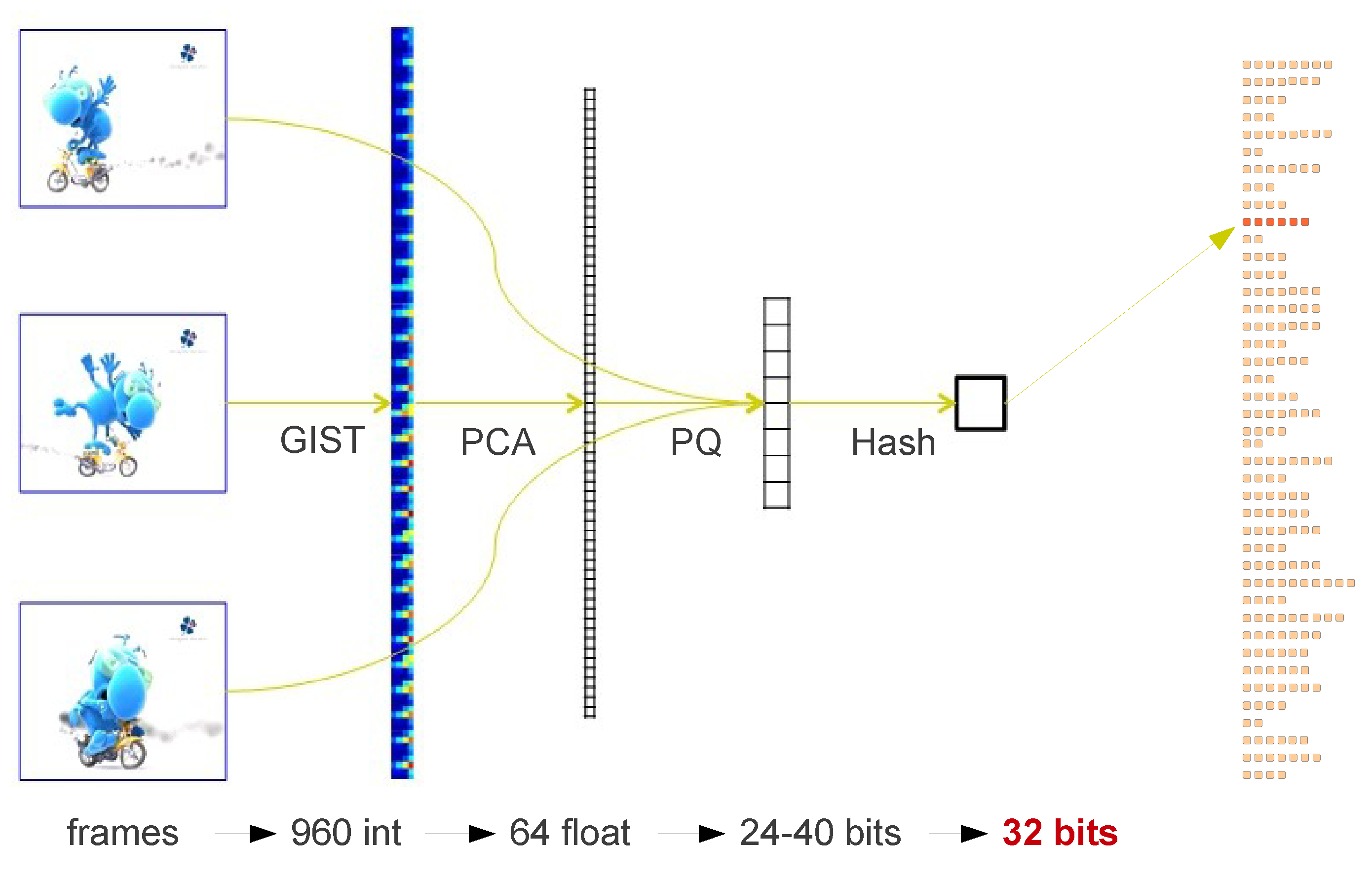
Near-duplicate pattern discovery in long video streamsDuplicates or near-duplicates mining in video sequences is of broad interest to many multimedia applications. How to design an effective and scalable system, however, is still a challenge to the community. In this paper, we present a method to detect recurrent sequences in large-scale TV streams in an unsupervised manner and with little a priori knowledge on the content. The method relies on a product k-means quantizer that efficiently produces hash keys adapted to the data distribution for frame descriptors. This hashing technique combined with a temporal consistency check allows the detection of meaningful repetitions in TV streams. When considering all frames (about 47 millions) of a 22-day long TV broadcast, our system detects all repetitions in 15 minutes, excluding the computation of the frame descriptors. Experimental results show that our approach is a promising way to deal with very large video databases. |
|
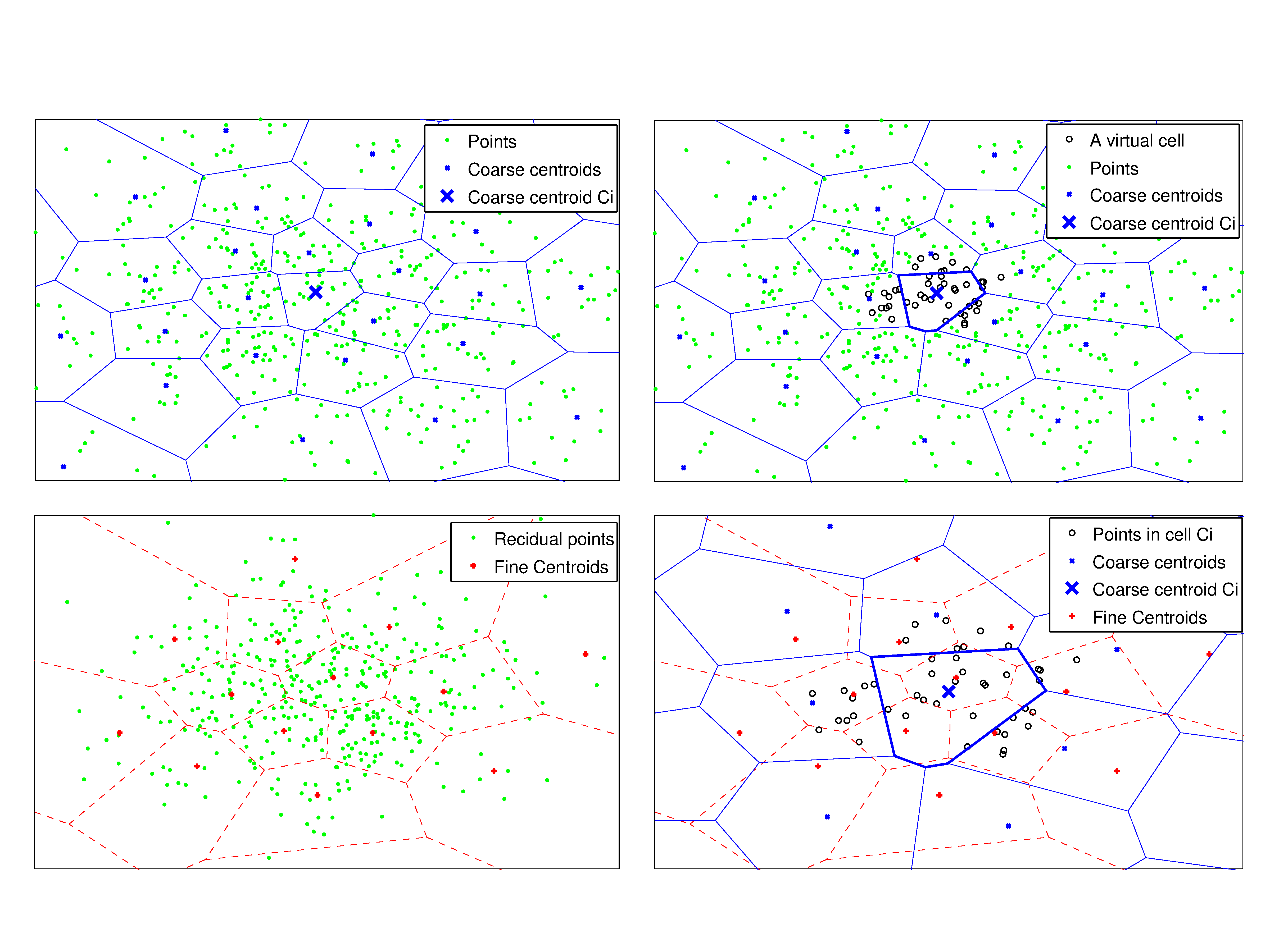
The Inverted Residual File (IVRF): a novel inverted index for approximate neareset neighbor searchWe propose a residual k-means based inverted index for approximate nearest neighbor search, which is named as the inverted residual index. It is a two-level indexing structure, in which each level produces a codebook; it finally partitions the space into small cells that are organied as tree-structure and save into an inverted file. In addition, we introduce a multi-assignment strategy to overcoming the diminishing return problems in search with high-dimensional data; we also design pruning strategies to balancing the trade-off between search qualities and speeds. All thanks to these new strategies and the low complexity of residual k-means, the proposed algorithm is able to process very large databases. Through experiments on several visual benckmarks, we have achieved very good ANN search results and have demonstrated the new index is comparable to any existing indexing structures for the same problem. |