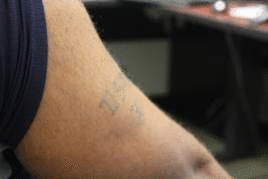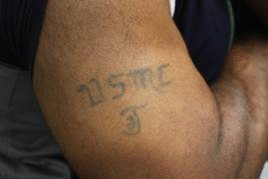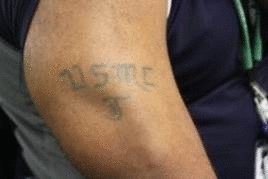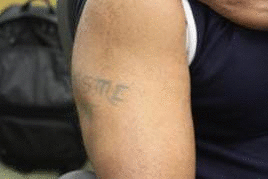
|
|
Project 6. Context-Sensitive Tattoo Segmentation and Classification
|
| Description: In object-centered semantic segmentation, information from the background
is considered as noise. However, for some objects, it is difficult to described them in terms of their
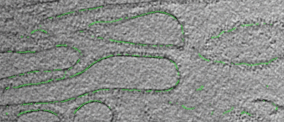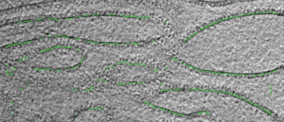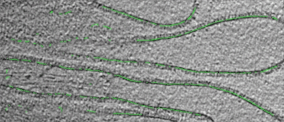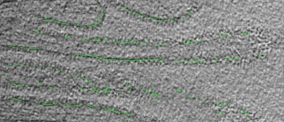
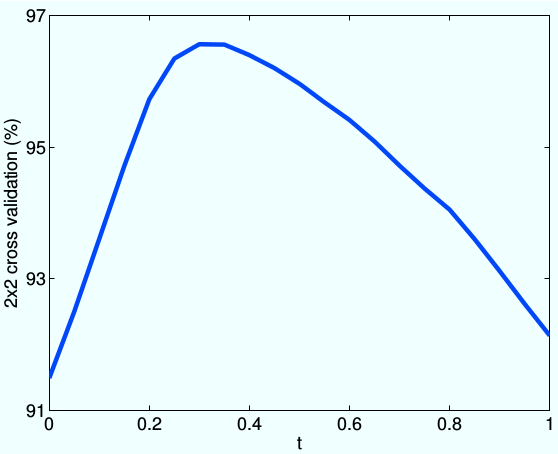
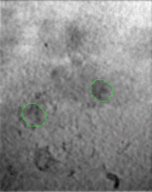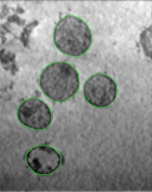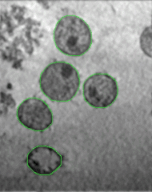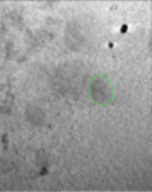
own appearance characters. In this work, we developed a context-sensitive semantic segmentation algorithm
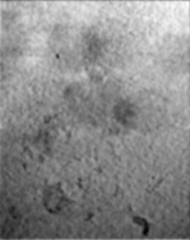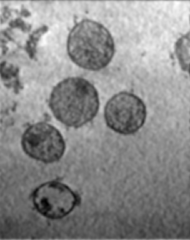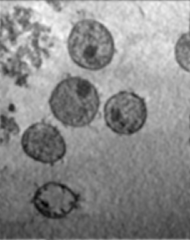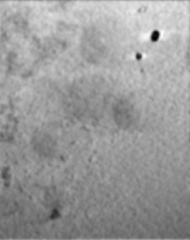
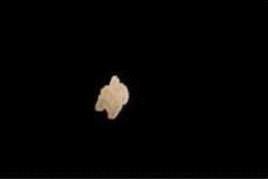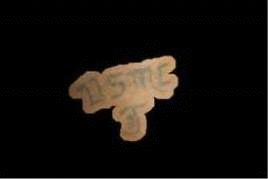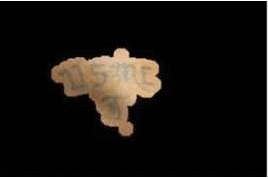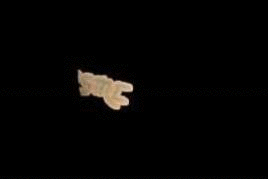
for extracting tattoos in an image. Segmentation of tattoo with unknown number of connected components
and arbitrary shapes is transferred to a figure-ground (tattoo-skin) segmentation.
We also applied our segmentation results on multiple tasks of tattoo classification and demonstrated
the state-of-the-art performance using our algorithm.
|
| Publication: Allen, Josef D., Nan Zhao, Jiangbo Yuan, Xiuwen Liu. "Unsupervised tattoo segmentation combining bottom-up and top-down cues." SPIE Defense, Security, and Sensing. International Society for Optics and Photonics, 2011. [Link][PDF] |